Readme
Hate Speech on Twitter: A Natural Language Processing Challenge
Want to look at the “official” presentation that goes with this project? Click here!
Overall Summary
About the Dataset:
The aim of this dataset is to determine if a set of 30,000 tweets contains hate speech relating to sexism and racism in order to create predictive models to identify such language in the future. Tweets are pre-labeled as either 0(not containing hate speech) or 1(containing hate speech).
This dataset is available online as a part of the Analytics Vidhya challenge series.
Skills Used in This Project:
Throughout the course of this project I had the chance to strengthen the following skills:
- Data Wrangling: The dataset came with only three features: id, label, and tweet. It was up to me to break down the info and get it to make sense. This involved cleaning the tweets for extraneous characters and symbols, creating my own “stop word” list of common filler words that didn’t have much impact on the sentiment of the tweet, and analyzing the accuracy of the labels.
- Natural Language Processing: Since this was my first time to experiment with Natural Language Processing I really dove into how keywords can (or can’t) signify semantics (meaning) in text. Using SciKit-Learn I processed the tweets into individual word-features and looked at the relationship between groups of word and meaning.
- Machine Learning/Predictive Modeling: While working through this project I quickly learned that using base keywords to create labels for machine learning can be completely inaccurate! Fun! This led me to create my own labels for the tweets using a list of my own keywords(which is ever growing).
Prerequisites/Project Process
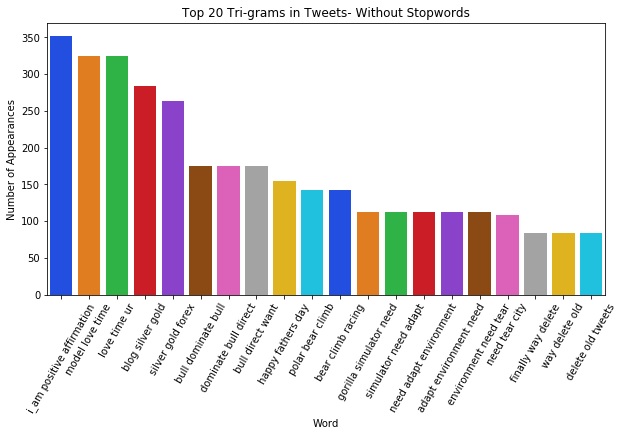
Exploratory Data Analysis (EDA)
Please see the provided presentation for a full break-down of my EDA process and (very pretty) visualizations!
Testing/Main Purpose of Project
Can we use our prelabeled data set to predict if a tweet is hate speech or not?